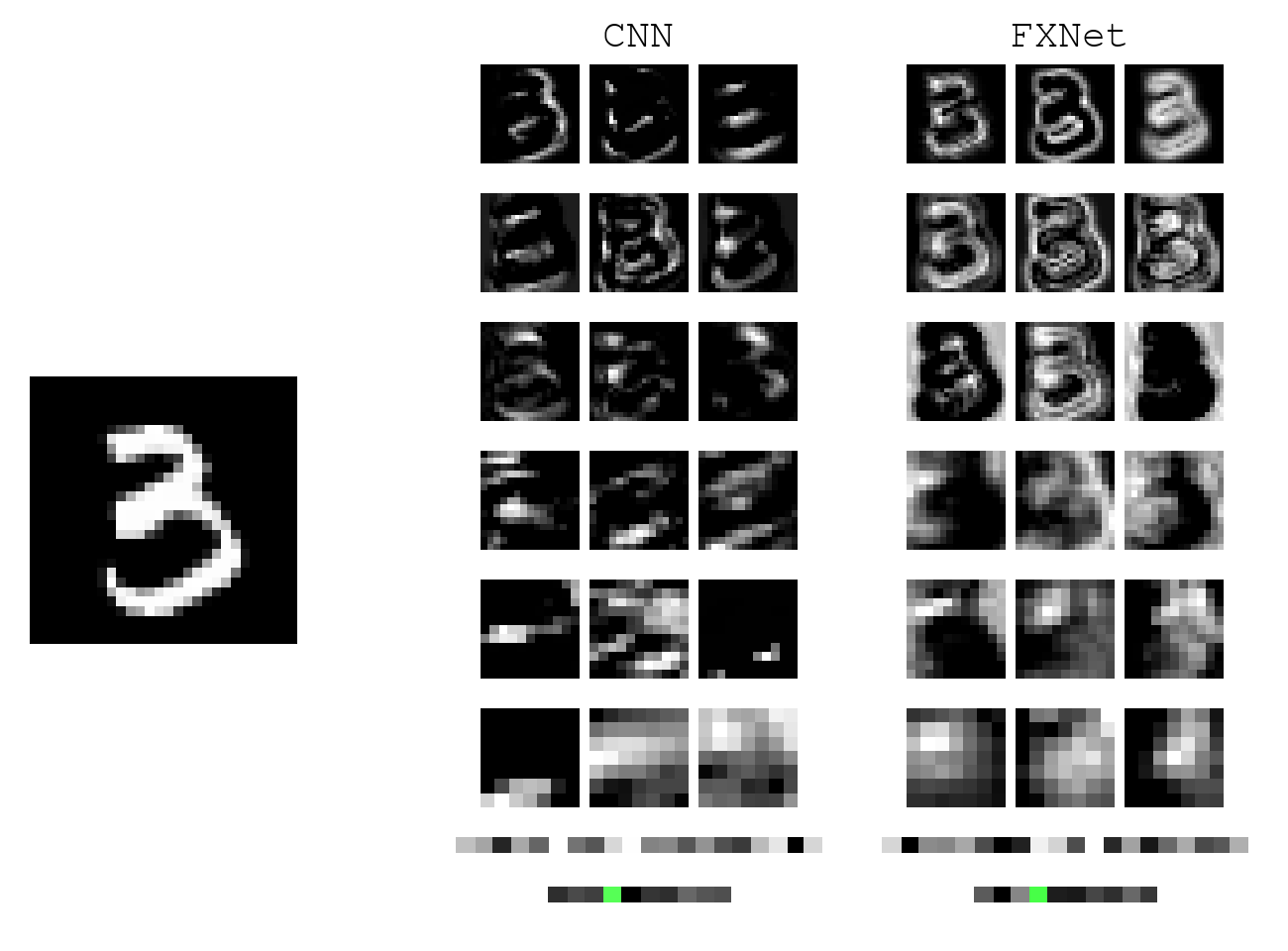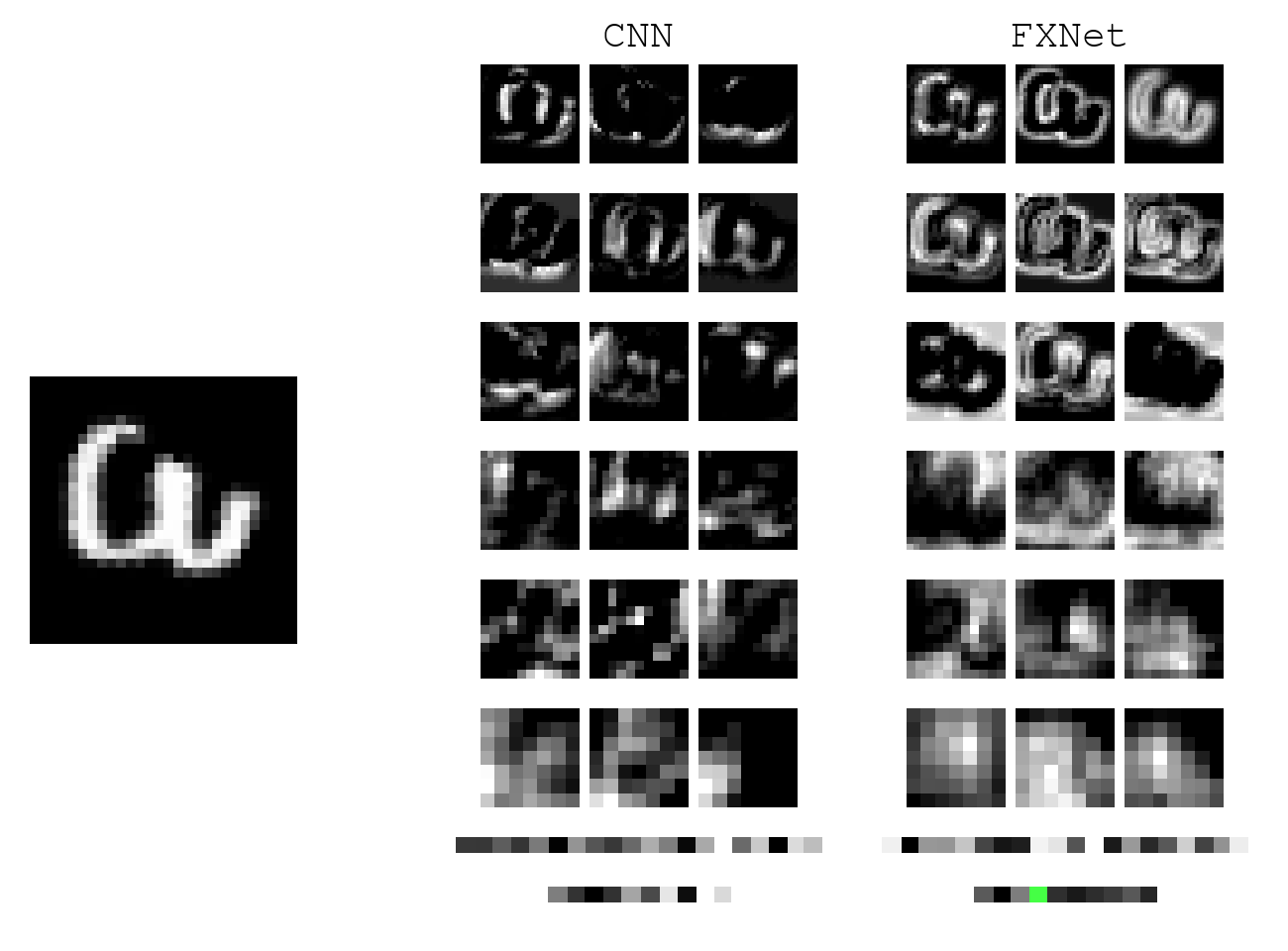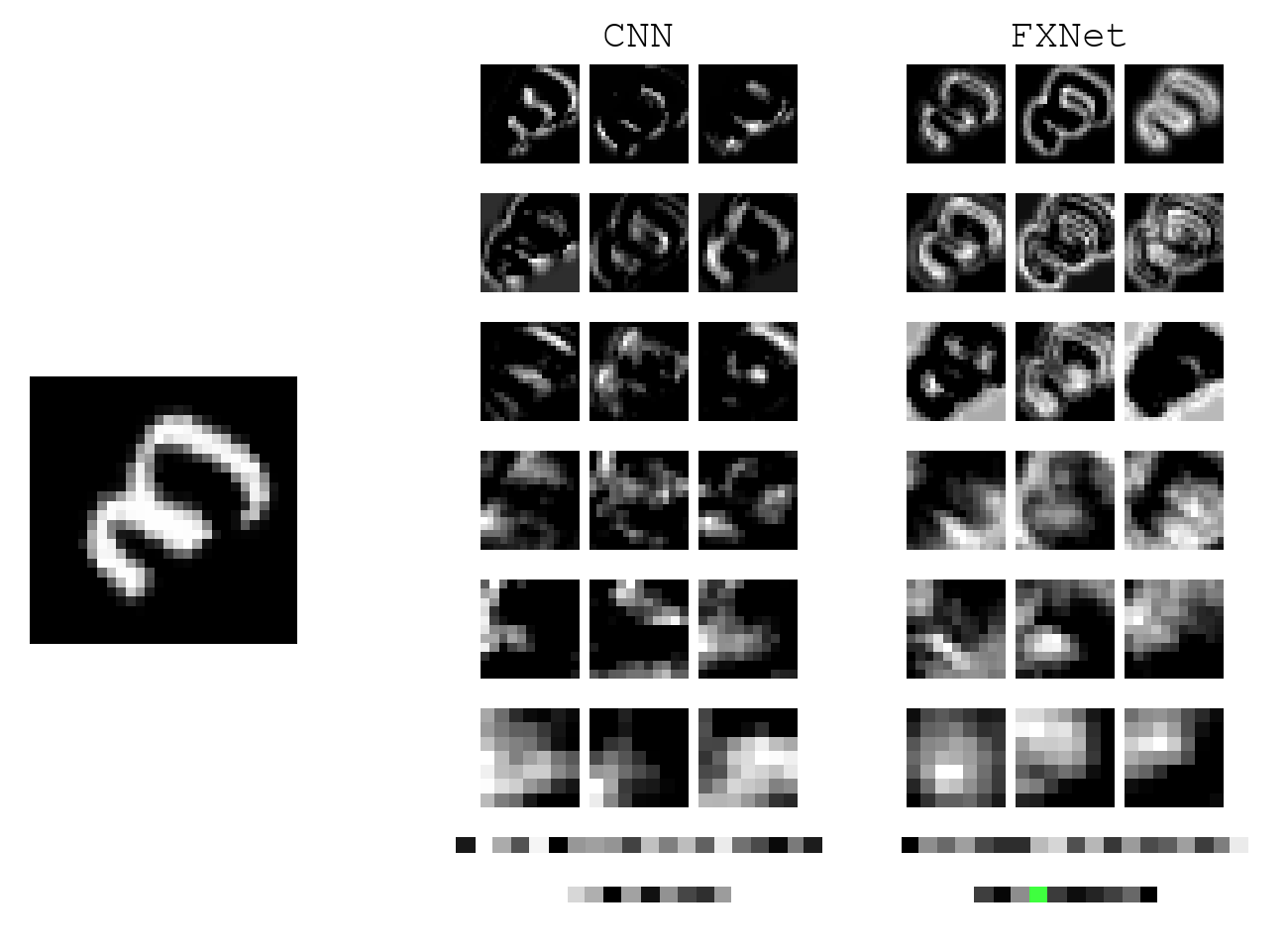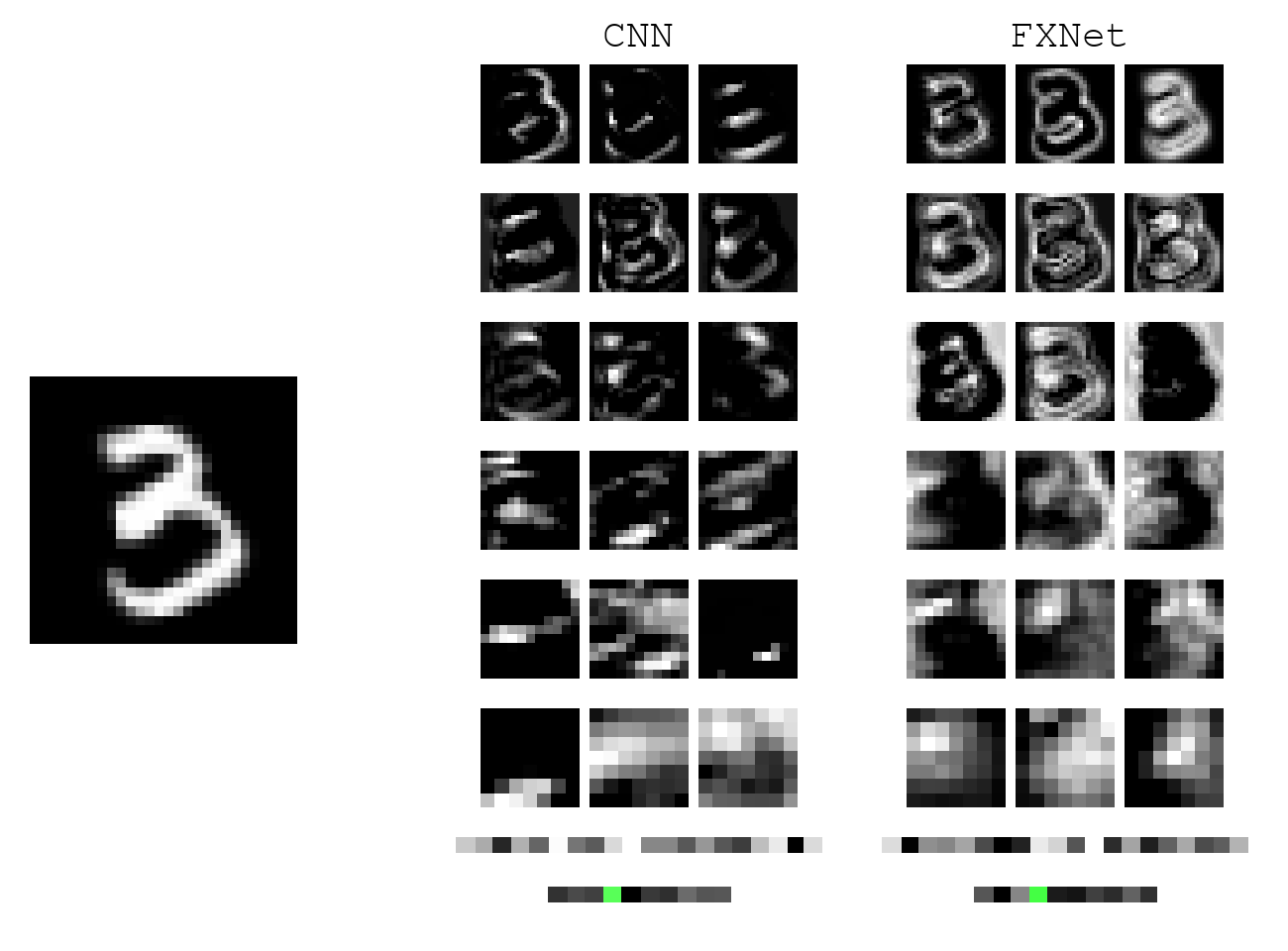
The main reason we are interested in creating a network that learns rotationally invariant features is that the satellite takes an image from all kinds of angles. Since an image is taken right above the ground, objects of all orientations will appear.
We achieve invariance through exploiting symmetry in viewing angles. With appropriate design, we can train MNIST digits with upright orientation and have prediction generalize to any random rotation. A typical CNN, on the other hand, would completely fail without test-time augmentation. Below shows a gif of the model in action. During test time, when the digit 3 is rotated, CNN features change drastically, and the prediction (bottom row) becomes erratic. For our model, the prediction is consisteny.